ChatGPT is becoming increasingly useful in our daily lives. Personally, it helps me with proofreading, generating programming code, summarize documents, and even replacing some of my Google searches. However, all conversations with ChatGPT are processed on OpenAI’s servers, requiring an internet connection for it to function properly. In this article, I will share the step-by-step guide on how to setup an offline ChatGPT-like AI system on your computer.
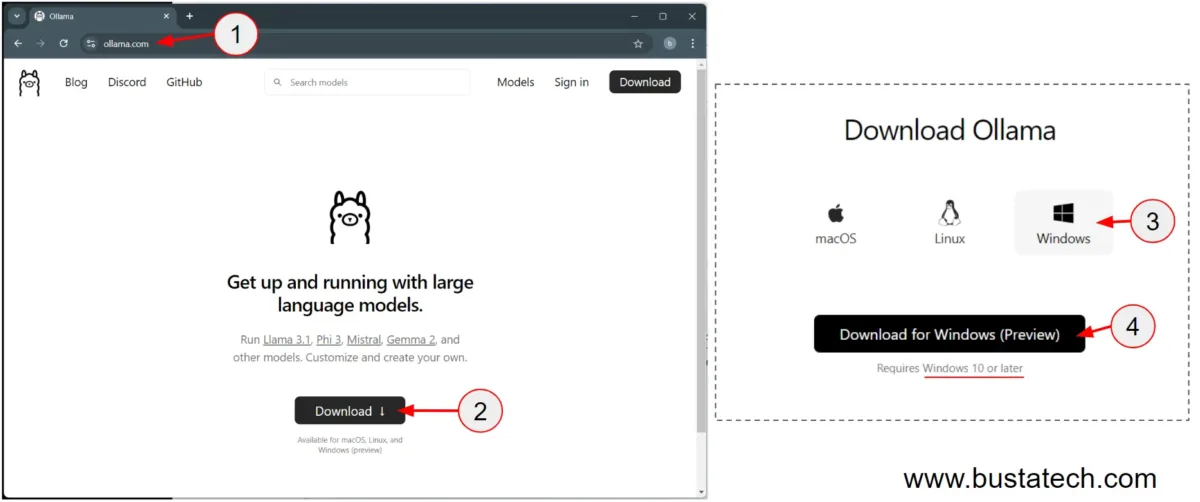
First, navigate to ollama.com and click the Download button. I am using Windows 11 for this demonstration, so I downloaded the installer for Windows. Note that installers for macOS and Linux are also available on the Download page.
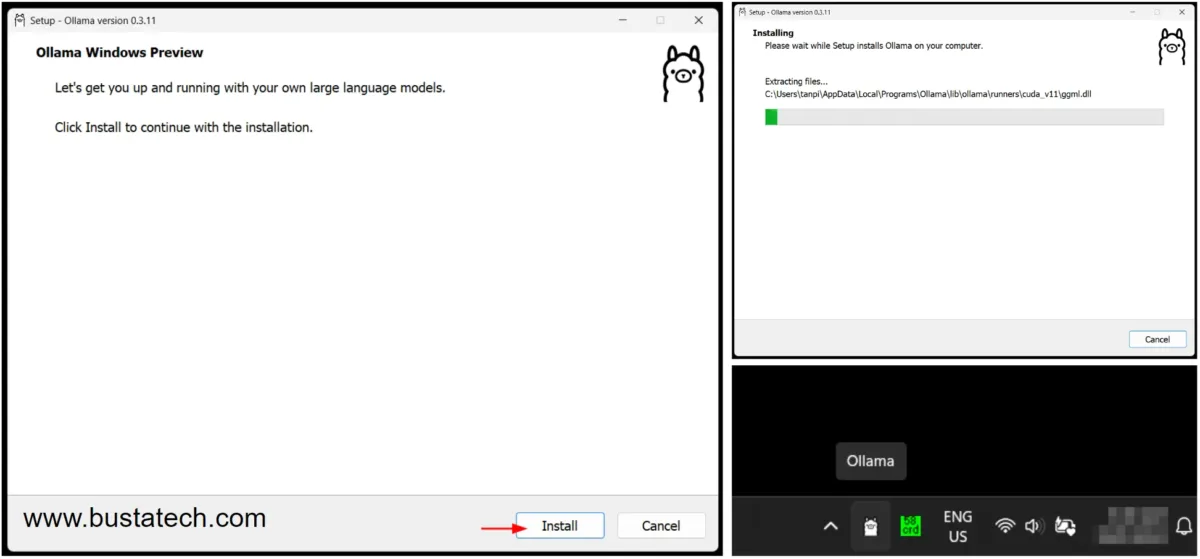
After the download is complete, launch the installer and follow the installation process. Once the installation is finished, you should see an Ollama icon in your system tray.
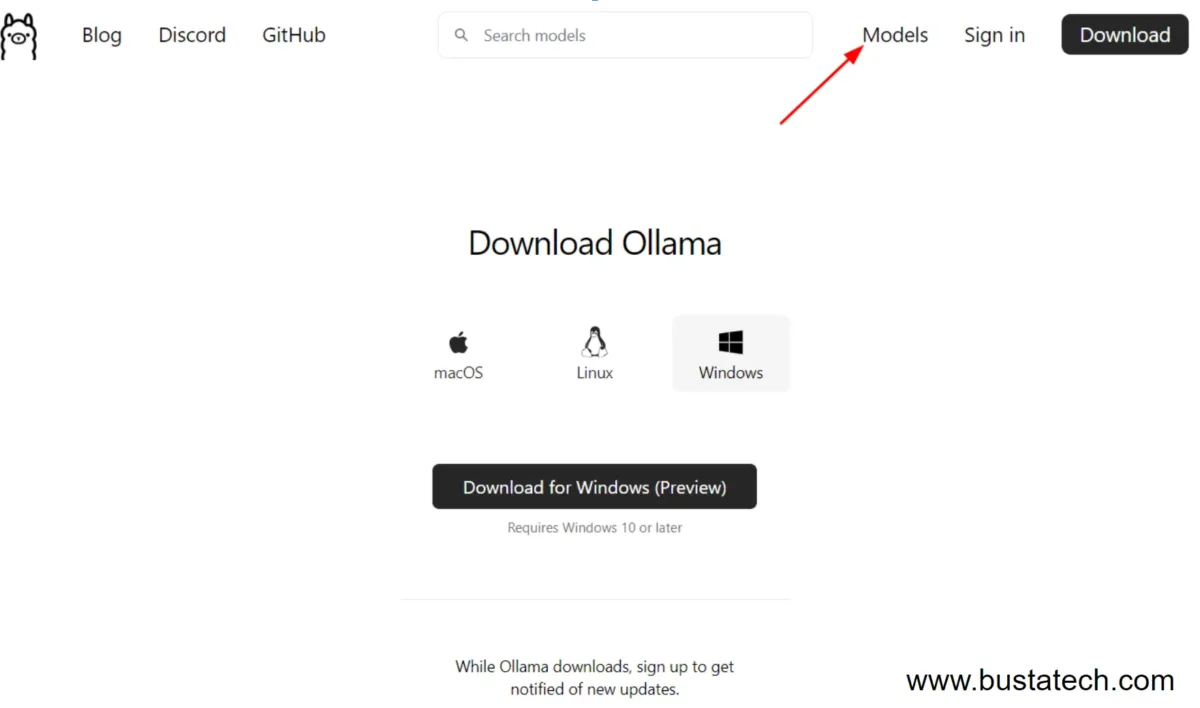
Next, navigate to the Models page on the Ollama website.
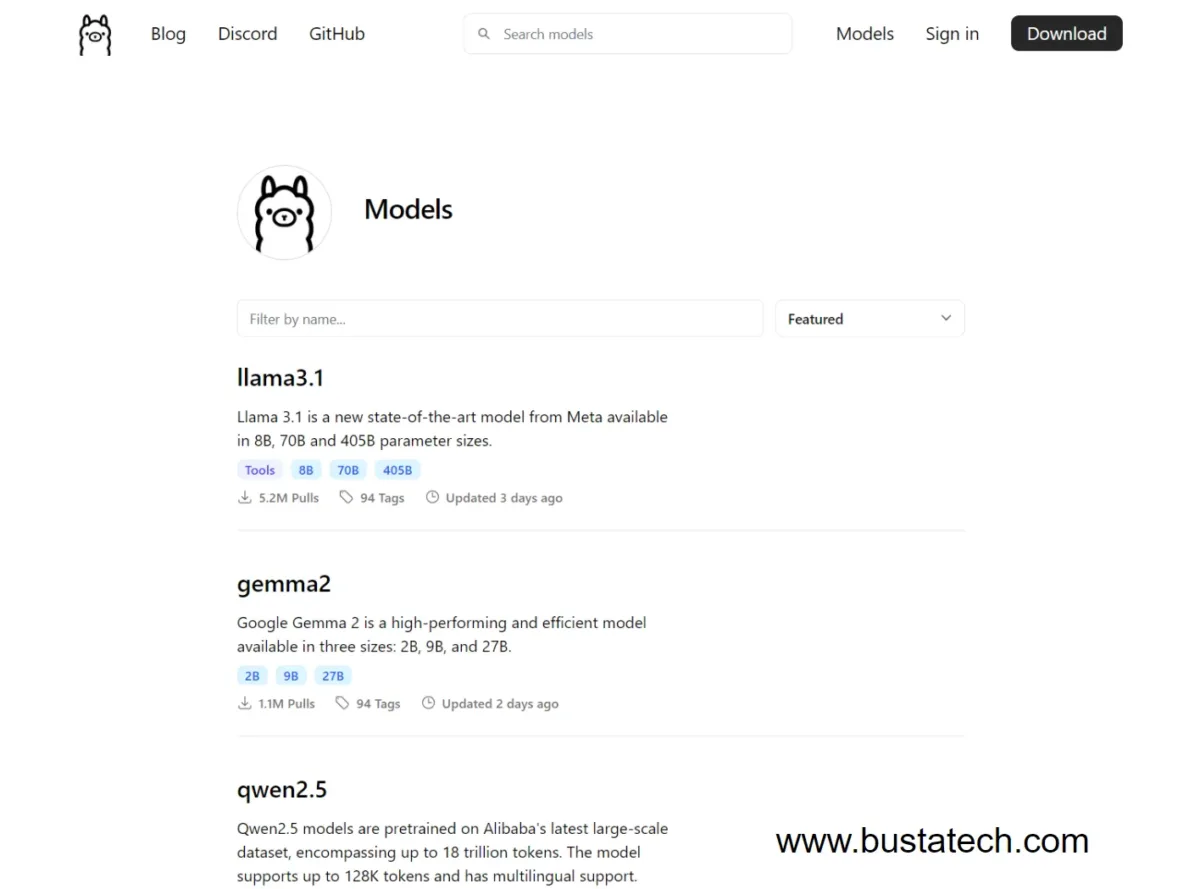
Here, you will see all the available models that you can install on your computer.
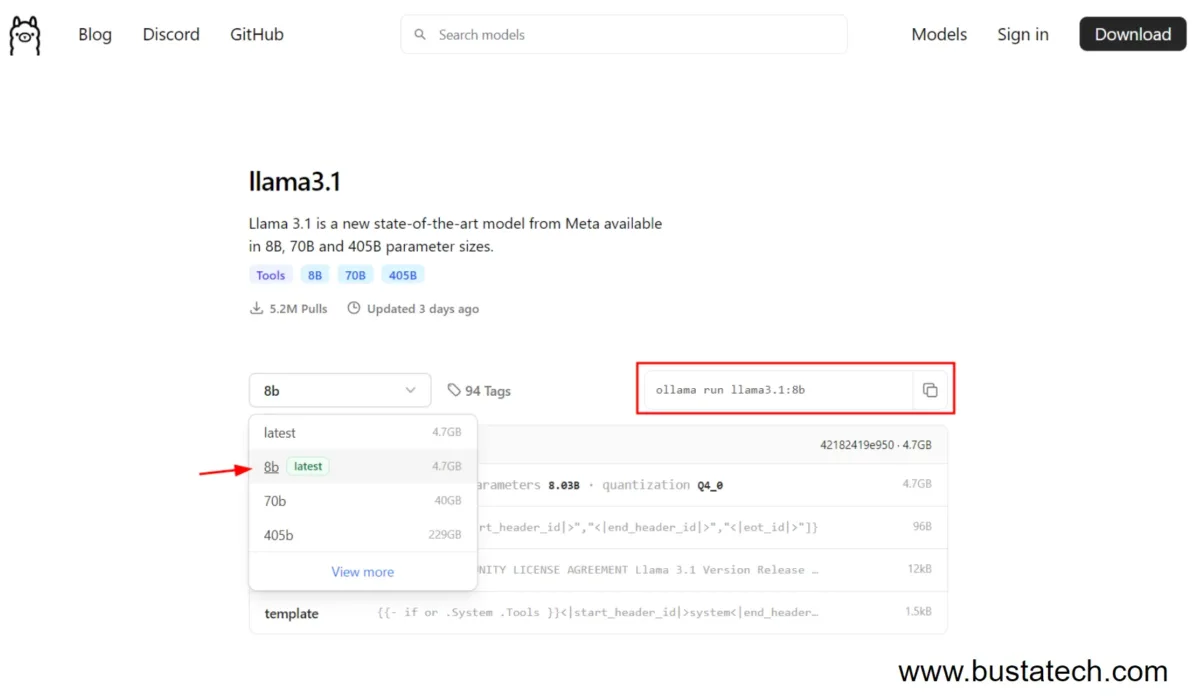
For this demonstration, we will be using the llama3.1 8b version. A quick explanation about the differences between 8b, 70b, and 405b: most AI models come in different parameter sizes, which affect the model’s size and the system requirements needed to run them. In my case, my laptop specs are i7-12800H CPU, 32GB RAM, and a GTX A2000 GPU with 8GB VRAM. I am only able to run the llama3.1 8b version smoothly. Unless you are using a very high-spec PC, I recommend starting with the 8b version.
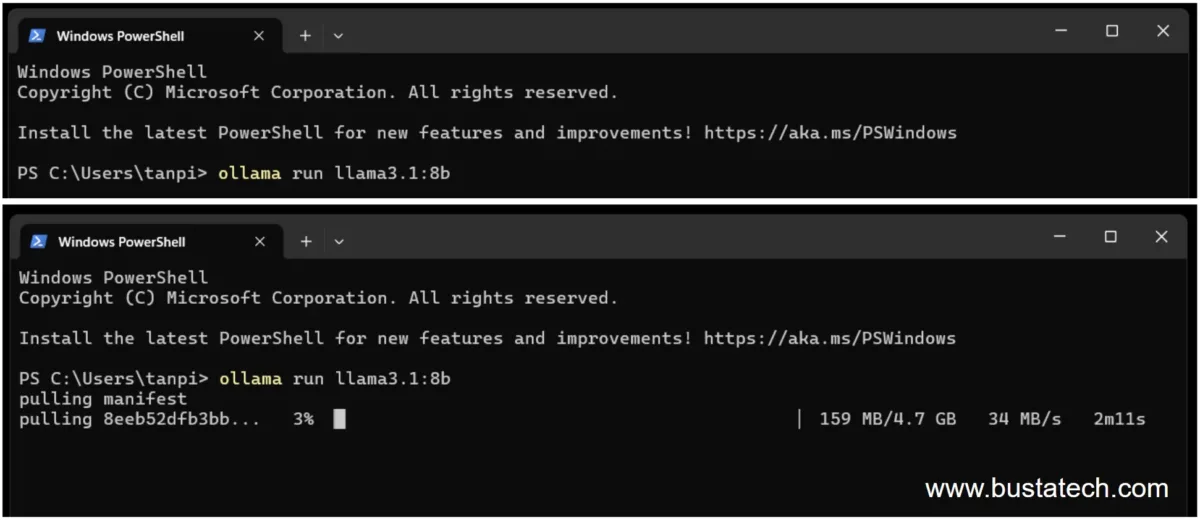
To install the llama3.1 8b version, you will need to run a command in Windows Terminal. Open a Terminal instance and execute the following command:
ollama run llama3.1:8b
This will automatically download the model and install it on your computer. Make sure that you have enough hard disk space for the installation; in the case of the llama3.1 8b model, it requires around 5GB.
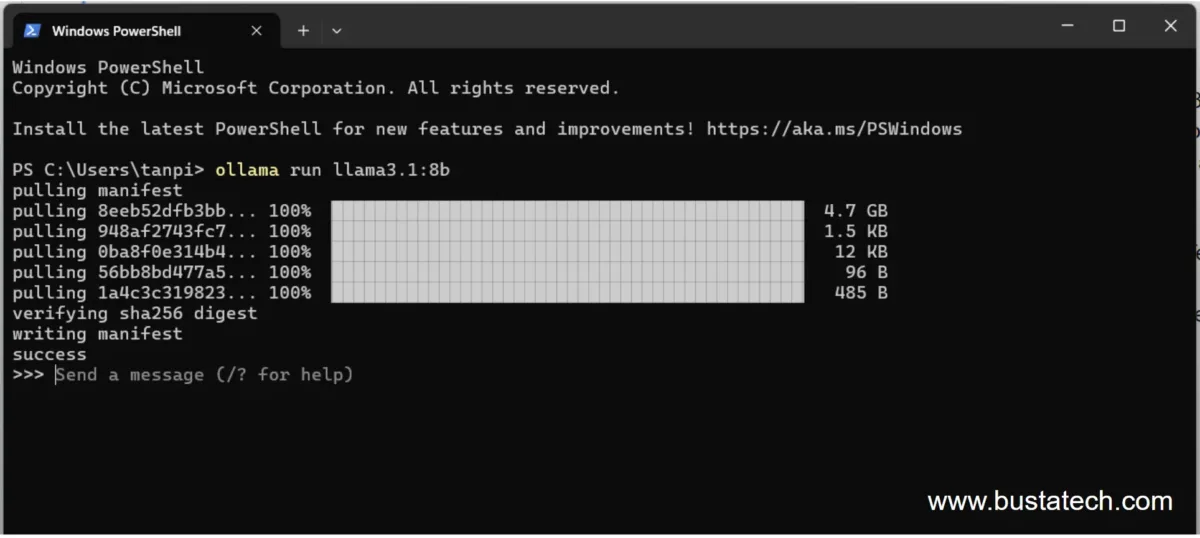
For me, the installation took around 2 minutes to complete. Immediately after installation, the system allows you to input your prompt to the AI.
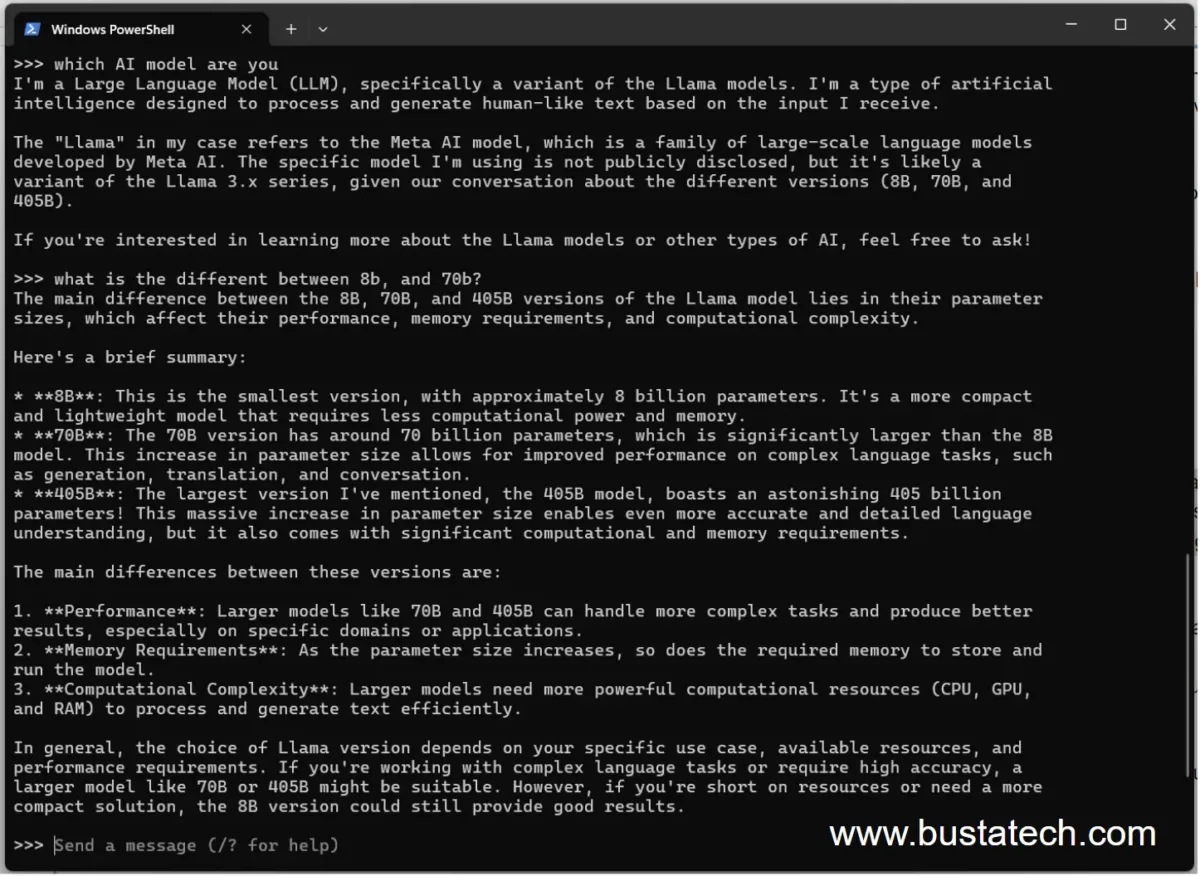
In my experience, it works similarly to ChatGPT, although ChatGPT may provide better responses. This could be due to the smaller 8b parameter size. Keep in mind that results may vary depending on the parameter size and model. Feel free to experiment with different models.
To exit the chat, simply type /bye.
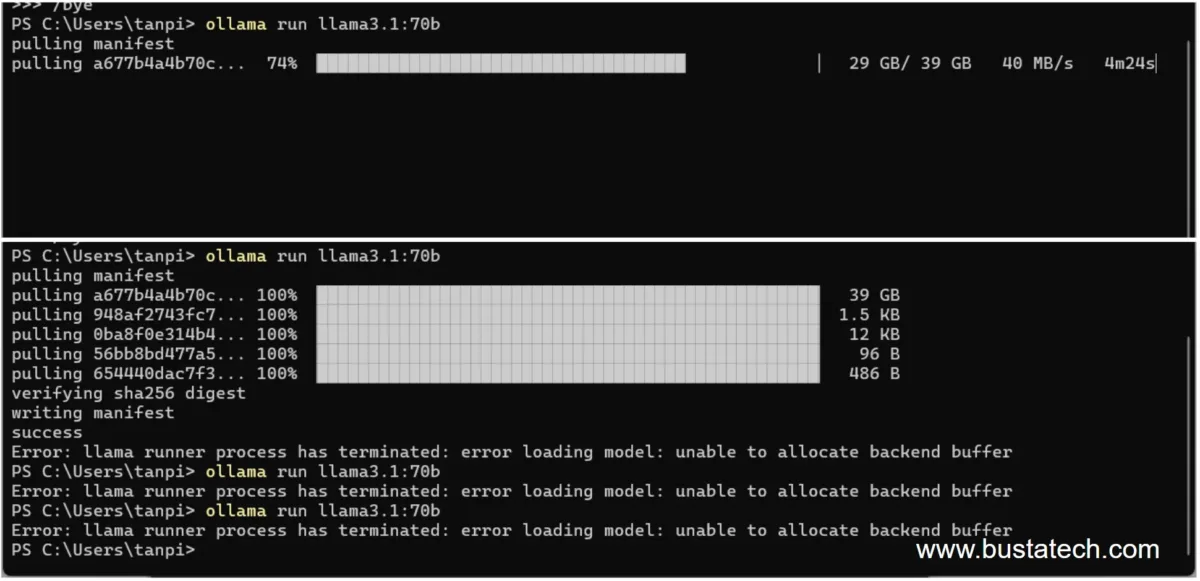
I also tried running the llama3.1 70b version on my laptop, but it displayed the error: ‘unable to allocate backend buffer’.
The largest model I tried is Gemma2 27B, and the output is laggy, as shown in the GIF above. It seems to have fully utilized the 8GB of GPU RAM and even used shared system RAM. I believe most large models will require a very high amount of GPU RAM to operate correctly.